大數(shù)據(jù)問(wèn)題解決方案 模式選擇與產(chǎn)品實(shí)現(xiàn)策略
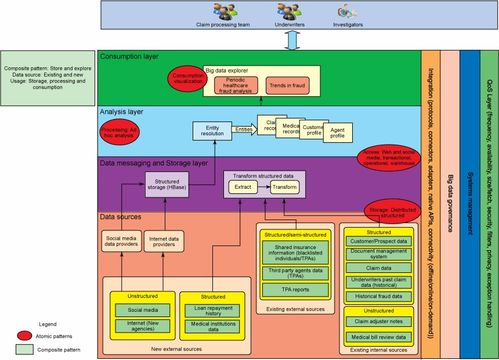
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,大數(shù)據(jù)問(wèn)題已成為企業(yè)數(shù)字化轉(zhuǎn)型的關(guān)鍵挑戰(zhàn)。針對(duì)大數(shù)據(jù)問(wèn)題,應(yīng)用科學(xué)合理的解決方案模式并選擇合適的產(chǎn)品,是提升計(jì)算機(jī)系統(tǒng)服務(wù)效率與精準(zhǔn)度的核心環(huán)節(jié)。
一、大數(shù)據(jù)問(wèn)題的主要特征與挑戰(zhàn)
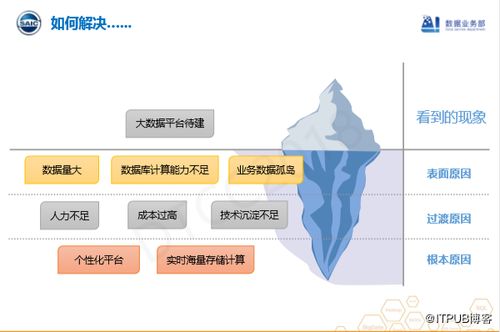
大數(shù)據(jù)問(wèn)題通常表現(xiàn)為數(shù)據(jù)量大、數(shù)據(jù)類型多樣、處理速度要求高以及價(jià)值密度低等特點(diǎn)。企業(yè)面臨的挑戰(zhàn)包括數(shù)據(jù)采集、存儲(chǔ)、處理、分析和可視化等多個(gè)環(huán)節(jié)。例如,金融行業(yè)需要實(shí)時(shí)處理海量交易數(shù)據(jù)以進(jìn)行風(fēng)險(xiǎn)控制,電商平臺(tái)需分析用戶行為數(shù)據(jù)以優(yōu)化推薦系統(tǒng)。
二、解決方案模式的應(yīng)用
1. Lambda架構(gòu)與Kappa架構(gòu)
Lambda架構(gòu)結(jié)合批處理與流處理的優(yōu)勢(shì),適用于對(duì)歷史數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)均有高要求的場(chǎng)景。Kappa架構(gòu)則簡(jiǎn)化流程,完全基于流處理,適合實(shí)時(shí)性要求極高的應(yīng)用。企業(yè)可根據(jù)業(yè)務(wù)需求選擇:如金融風(fēng)控系統(tǒng)可能采用Lambda架構(gòu),而物聯(lián)網(wǎng)實(shí)時(shí)監(jiān)控可能更傾向于Kappa架構(gòu)。
2. 數(shù)據(jù)湖與數(shù)據(jù)倉(cāng)庫(kù)結(jié)合模式
數(shù)據(jù)湖存儲(chǔ)原始數(shù)據(jù),支持多種數(shù)據(jù)類型;數(shù)據(jù)倉(cāng)庫(kù)存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù),便于分析。結(jié)合兩者可實(shí)現(xiàn)靈活性與高效性的平衡。例如,醫(yī)療健康領(lǐng)域可將患者影像數(shù)據(jù)存入數(shù)據(jù)湖,結(jié)構(gòu)化病歷數(shù)據(jù)存入數(shù)據(jù)倉(cāng)庫(kù),以支持綜合診斷分析。
3. 微服務(wù)與容器化部署
通過(guò)微服務(wù)架構(gòu)將大數(shù)據(jù)系統(tǒng)分解為獨(dú)立服務(wù),結(jié)合容器化技術(shù)(如Docker和Kubernetes)提升部署彈性和資源利用率。這種模式特別適合需要快速迭代和擴(kuò)展的互聯(lián)網(wǎng)服務(wù)。
三、產(chǎn)品選擇與實(shí)現(xiàn)策略
- 存儲(chǔ)層產(chǎn)品選型
- 分布式文件系統(tǒng):HDFS適用于大規(guī)模批處理場(chǎng)景,如云存儲(chǔ)備份系統(tǒng)。
- NoSQL數(shù)據(jù)庫(kù):MongoDB適合存儲(chǔ)半結(jié)構(gòu)化數(shù)據(jù),Cassandra則在高寫入場(chǎng)景中表現(xiàn)優(yōu)異,可應(yīng)用于社交媒體的用戶數(shù)據(jù)管理。
- 云存儲(chǔ)服務(wù):AWS S3或阿里云OSS提供高可用的對(duì)象存儲(chǔ),適合混合云環(huán)境的數(shù)據(jù)歸檔。
- 處理層產(chǎn)品選型
- 批處理框架:Apache Spark因其內(nèi)存計(jì)算優(yōu)勢(shì),廣泛用于數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)任務(wù)。
- 流處理框架:Apache Flink提供低延遲處理,適用于實(shí)時(shí)欺詐檢測(cè)系統(tǒng)。
- 查詢引擎:Presto或Impala支持跨數(shù)據(jù)源快速查詢,適合企業(yè)級(jí)數(shù)據(jù)倉(cāng)庫(kù)分析。
- 管理與調(diào)度工具
- 工作流調(diào)度:Apache Airflow可編排復(fù)雜的數(shù)據(jù)管道,確保ETL流程的可靠性。
- 集群管理:Apache Ambari或Cloudera Manager簡(jiǎn)化Hadoop生態(tài)系統(tǒng)的運(yùn)維。
四、計(jì)算機(jī)系統(tǒng)服務(wù)的實(shí)施建議
1. 需求分析與架構(gòu)設(shè)計(jì)
首先明確業(yè)務(wù)目標(biāo),例如是降低延遲還是提高吞吐量。設(shè)計(jì)架構(gòu)時(shí)需考慮可擴(kuò)展性和容錯(cuò)性,如采用多副本存儲(chǔ)防止數(shù)據(jù)丟失。
2. 產(chǎn)品集成與測(cè)試
選擇兼容性強(qiáng)的產(chǎn)品組合,并通過(guò)概念驗(yàn)證測(cè)試性能。例如,將Kafka用于數(shù)據(jù)采集,Spark Streaming進(jìn)行實(shí)時(shí)處理,最終結(jié)果存入Elasticsearch以支持快速檢索。
3. 運(yùn)維與優(yōu)化
建立監(jiān)控體系,使用Prometheus和Grafana跟蹤系統(tǒng)指標(biāo)。定期優(yōu)化資源配置,如調(diào)整Spark executor內(nèi)存以提升作業(yè)效率。
五、案例實(shí)踐
以智慧城市交通管理系統(tǒng)為例:采用Lambda架構(gòu)處理歷史流量數(shù)據(jù)(批處理)和實(shí)時(shí)傳感器數(shù)據(jù)(流處理);存儲(chǔ)層使用HDFS和HBase;處理層采用Spark進(jìn)行擁堵模式分析;通過(guò)Tableau實(shí)現(xiàn)可視化展示。該方案顯著提升了交通調(diào)度效率。
大數(shù)據(jù)問(wèn)題的解決需要模式與產(chǎn)品的有機(jī)結(jié)合。企業(yè)應(yīng)基于具體場(chǎng)景選擇架構(gòu)模式,并搭配成熟的產(chǎn)品工具,同時(shí)注重系統(tǒng)服務(wù)的全生命周期管理,從而實(shí)現(xiàn)數(shù)據(jù)價(jià)值最大化并推動(dòng)業(yè)務(wù)創(chuàng)新。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.pic16.cn/product/8.html
更新時(shí)間:2026-06-07 02:39:36